09.07.2020 17:13
tag2domain - a system for labeling DNS domains
Tag2domain - doing proper statistics on domain names
In the course of nic.at’s Connecting Europe Facilities (CEF) project CEF-TC-2018-3 we were able to focus on some long overdue but relevant research: a tagging / labeling database of domain names (in the following, we will use the words “tag” and “label” interchangeably).
This project was also presented at the Registry Data Nerds (RDN) virtual meeting on the 30th of June 2020. Slides are available on github.
What is "tag2domain"?
Simply said, this is a structure to tag DNS domain names with arbitrary labels. Initially this seems like an easy task. However, when looked at closely, it is paramount to implement this properly. Not only will all future statistics on domains depend on a proper tagging. Doing proper statistics is anything but easy. “He who counts, will count wrongly” seems to be the motto of statistics (in German: “der, der misst, misst Mist”).
Hence, any type of labeling / tagging service must
- Be future-proof
- Be flexible
- Encompass all possible tagging systems we might come up with in the future
- Easily fit into and connect to existing databases and datasets of domain names
- Be easily query-able
- Be useable for answering ad-hoc statistical questions
Not an easy task.
The proposed solution
We arrived – inspired by the MISP system as well as ENISA’s RIST taxonomy – at the following schema:
A tagging system for a particular statistical domain shall be called “taxonomy”.
A taxonomy consists of a name (e.g. the “low content domain names taxonomy”) and some meta-information (such as if it may be used for domain names or IP addresses or both).
Associated with a taxonomy, is a list of possible “tags” (i.e. labels or names which we might assign to domain names (or IP addresses)). Think of this as an enum (as in the programming language C) or a fixed list of possible values. Each taxonomy has a fixed number of tags and there should always be an “OTHER” tag which is a bucked for counting those domains which do not fall into any of the existing tags within that taxonomy.
In addition, to add a second layer (and thus flexibility), tags might have values if they they are assigned to a domain name (or IP address).
Example:
Let’s assume, we have a taxonomy which is capable of assigning industry sectors to domains: the DIT (domain industry taxonomy).
It consists of a taxonomy name (“DIT”), a fixed list of possible tags (“Agriculture, Forestry, Fishing”, “Automotive”, “Beauty and Perfume”, “Cleaning and Facility Management” , etc..).
Each possible tag may have a value associated with it which is basically a sub-category.
Example: “Automotive” -> “Maintenance”.
In machine readable form, these taxonomies, tags and values shall be presented as:
taxonomy:tag = value
Example:
DIT:Automotive = Maintenance
(This is inspired by the MISP taxonomies structure. A taxonomy is thus basically a namespace for a set of tags).
It is easy to see that this structure is future-proof. If a given taxonomy does not fit your needs, it’s trivial to invent a new one with the required tags. Flexibility is also given.
A taxonomy shall always be registered at the taxonomy registry (operated by CIRCL, please issue pull requests to their repository). A taxonomy shall be given in the machine-tag format.
How to use it and how to fit a taxonomy and tags to existing databases/tables of domain names?
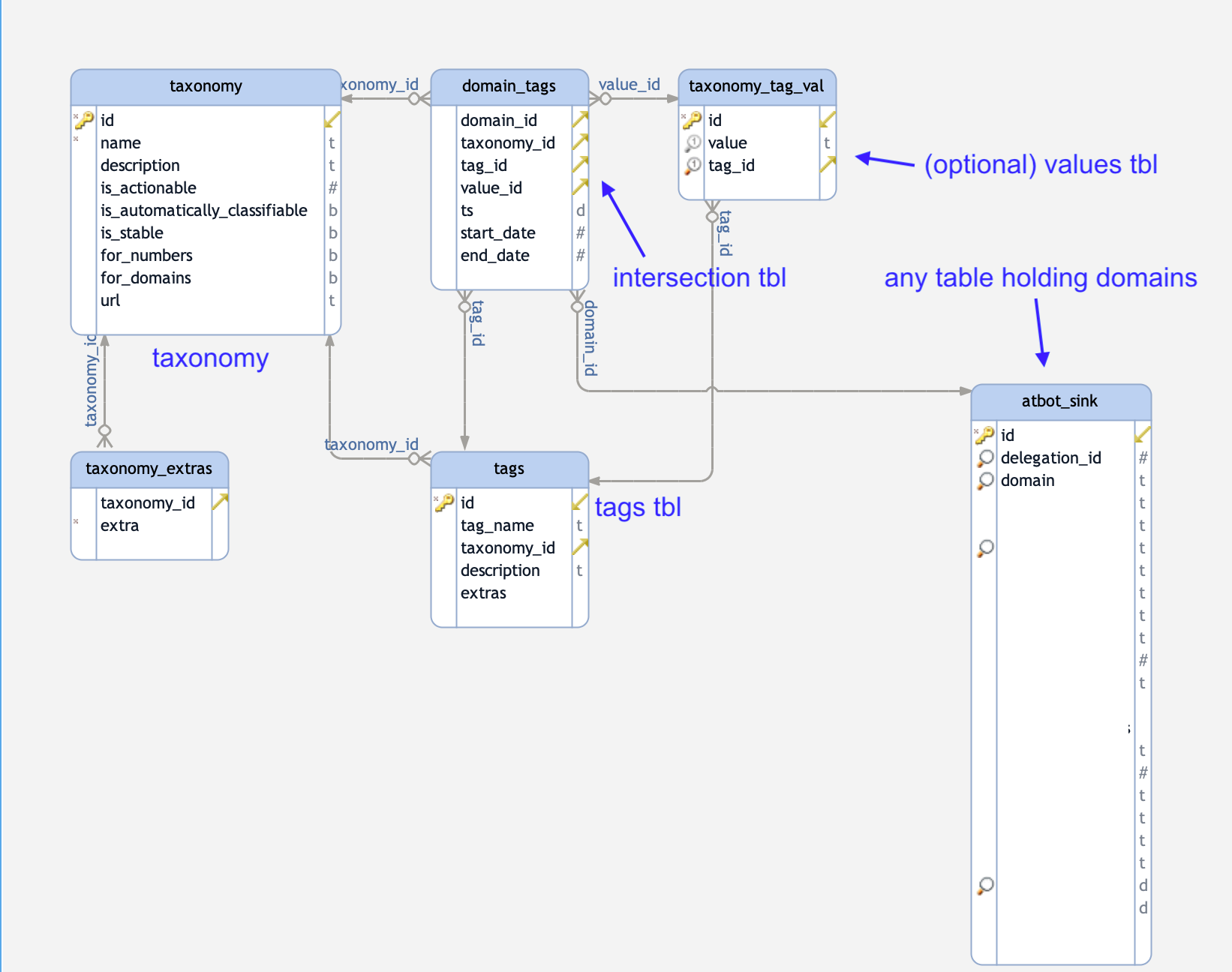
We created a sample mapping structure including documentation on our github repository.
One important thing to remember is that:
- Every mapping is time-dependent: a mapping of domain name to tag only exists at a specific point (or interval) in time. Therefore, any intersection tables between tags and domains (see the github link above) always need to include a timestamp which indicates validity
- Mappings should be done automatically. There is no golden rule on how to create a mapping. It is domain specific for each taxonomy. An example for mapping domains names to a “is a first name (Y/N)?” – tag is a word splitting algorithm which has a large dictionary of common first names. Other approaches will have to use machine learning and natural language processing libraries.
Querying the tag2domain database
We created a small container based microservice which implements a query interface, called “tag2domain-api”.
It supports the following RESTful API endpoints:
/api/v1/taxonomies/all ….get all possible taxonomies
/api/v1/tags/all … get all possible tags (for all taxonomies)
/api/v1/taxonomies/bydomain/{domain} … get all taxonomies for a given domain.
/api/v1/tags/bydomain/{domain} … get all tags for a given domain
/api/v1/domains/bytag/{tag} … get a list of all domains which match a specific tag
/api/v1/domains/bytaxonomy/{taxonomy} … get a list of all domains, which are in a specific taxonomy
Let us know, what you think. The author of this blog post can be reached via github or at kaplan@cert.at.
This blog post is part of a series of blog posts related to our CEF Telecom 2018-AT-IA-0111 project, which also supports our participation in the CSIRTs Network.
